课题类别:青年创新人才项目
课题项目:数据可视化平台的建设研究
项目批准号:2017kqncx266
经费资助:6万
项目负责人:颜远海
项目成员:杨莉云,吴宪传,黄梦莹,段晓聪
论文成果名称:
本课题共完成论文5篇,一篇科技核心期刊,两篇b类,二篇普刊,2件软件著作权。
论文1:颜远海.基于评论数据的满意度模型设计研究[j].江西科学2021.02
论文2:颜远海.基于q矩阵特征提取的建模及可视化分析[j].江西科学2020.06
论文3:颜远海.基于关联规则映射的电力物联网用户侧数据深度挖掘[j].吉林大学学报(信息科学版). 2022.03(科技核心)
论文4:yuan hai yan.parameter selection strategy for frequent itemsets inassociationanalysis.american journal of mathematical and computer modelling[j].2020.06
论文5:mengying huang* , yuanhai yan, lijuan xu, lihong ye;using warshall to solve the density-linked densityclustering algorithm;american journal of mathematical and computer modelling[j].2020.01
软件著作权:
软件名称:数据可视化分析处理系统v1.0;登记号:2020sr0201012;
软件名称:华商教育直播课堂系统[简称:教育直播]v1.0;登记号:2020sr0203520
论文成果简介:
成果1:《基于评论数据的满意度模型设计研究》
学术价值:本文从真实数据集着手,重点围绕北京短租行业客户满意度建模分析。对商家提供的服务满意度进行评分过程中也重点分析了客户情感趋势,并进一步将趋势分解为情感程度和情感极性两方面。通过不断的特征词分析形成同主题词汇表、情感词汇得分表。基于这些表的完善设计,计算基于某商家的每一条得分、某商家的综合得分。创新性加入了整体客户情感趋势值( st),该值能够反应整体行业规范程度,以及所突出的问题等,本文认为商家的评论得分也会受整体情感趋势的影响。根据整体行业趋势值( st)和客户评论得分计算出非标准化满意度值( nss),并对nss进行满意度标准化( ss)计算。在标准化过程中,考虑到行业发展规律下的满意度值,即满意度值提升速度随着得分增加而越来越慢。
成果2:《基于q矩阵特征提取的建模及可视化分析》
学术价值:本文本文从结合q矩阵理论,对数据进行去除噪声数据处理,并对合理数据进行数据统计与分析,建立属性权重、属性关联权重、属性间路径权重,通过算法计算。实验证明,属性权重值属性间关联权重值计算方式,权重越大,对特征提取的贡献值也越大,数据集特征同样也取决于属性间路径权重,如果某路径值越大,代表着该路径趋势越明显,出现的概率越大;反之,概率越小。本文研究应用可用于对主体(比方说公司、客户、人际关系等)间关联性分析,并为之提供科学的依据,但是所考虑的因素有限,比方说属性值只考虑了二值划分,定义权重因素过于依赖数据样本等。基于本实验研究,还有很多工作需要深入研究,比方说考虑更多因素来定义权重问题,考虑多值属性的关联研究等。
成果3:《基于关联规则映射的电力物联网用户侧数据深度挖掘》
学术价值:电力数据中蕴含着大量的有用信息,随着电网信息化水平的不断提升,因此在巨大规模数据集里挖掘有价值信息这一操作,逐渐成为电网规划建设、增容改建、可靠运行的主要助推剂。计算机技术与信息技术高速发展,推动了数据挖掘技术在电力领域中的普及与应用,使深层次的电网数据挖掘成为可能。
以数据挖掘为技术支撑,引入支持向量机与靶心度优化算法,建立出电力信息系统网络安全态势评估模型与电压暂降严重度评估模型,确保电网安全稳定运行;而郭阳等人则从电力企业内部管理角度,利用大数据挖掘技术,提取出电力企业的影响因素历史特征,经聚类分析,构建出电力企业评价体系,为决策者提供可行的管理建议。
互联网技术的革新推动了电力系统与物联网的耦合发展,电网用户规模日益庞大使用户侧数据量持续上升,因此本文面向电力物联网,设计一种新的用户侧数据深度挖掘方法。关联规则是较为普及且有效的一种数据规律发现策略,令无法确切描述的信息都实现清晰展示,且可以提升挖掘精准度。本文根据数据集之间的关联规则映射相关性,深度挖掘电力物联网用户侧数据,以期为供电管理奠定决策依据。以优化数据挖掘方法性能为目标,从以下几个方面做进一步探究:通过汇总大量更详实、更准确的用户侧数据;以此建立自动挖掘系统,实现挖掘自动化与数据可视化,进一步优化电网领域经济性。
成果4:《parameter selection strategy for frequent itemsets inassociation analysis》
学术价值:本文中参数的选择更多考虑经济利益值的影响,即也符合社会心理。但对于决策者来说,它不完全依赖它,会有外部次要因素,所以本文的结论可以是用作参考值,在二分搜索实验中,我们有一个假设问题,即当p值小于等于1时(收益损失或等于),参数值(主要是con或sup值)被认为太低,并进行调整向上;反之,p值越大,相应的参数值被适当降低。在这篇文章中,有一些自定义参数值。例如,p值为根据预测之间的关系确定经济性和决策成本。不同的公司会有识别p值的不同方法。p值是通过为每个频率分配固有值权重来计算项集。例如,l值的定义是参数值的稳定性。在实验中,l=0.01。设置这个参数的目的是为了能够产生稳定的参数值,也是设置为的退出条件在不产生无限循环的情况下促进实验。因此,解释参数选择的问题策略,我们必须固定某些参数以更好地解释结论,为取得稳定的经济效益,本文的主要内容是希望实验算法将用于说明决策追求的是p值,同时不忽略关联规则的数量。参数值应设置在可接受的范围内。本文中的m值。还有很多问题需要解决在本文中解决,如是否假设前提真的很合适,l值的合理策略,以及数据大小对参数的各种影响都会有问题需要解决的问题。
成果5:《using warshall to solve the density-linked density clustering algorithm》
学术价值:聚类算法在数据挖掘、模式识别和机器学习等领域有着广泛的应用,它是数据挖掘技术中的重要组成部分。海量数据的出现,使数据挖掘技术的应用层出不穷,其中聚类分析是大数据处理的基本操作。本文研究了密度聚类(dbscan)算法,做了相应的改进,为聚类算法的应用提供参考。
针对密度聚类算法计算的复杂性,提出一种利用warshall算法降低其复杂性的改进算法w-dbscan。在密度聚类算法中,相似度高的数据是密度相连的,本文构造了一个矩阵(
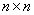 ),其中元素(x,y)标记为1指的是数据x和y是直接密度可达,然后利用warshall算法计算该矩阵的可达矩阵,可达矩阵指密度相连的数据。通过warshall算法,将求解密度相连问题转化为求解可达矩阵问题,降低了算法的复杂性。
),其中元素(x,y)标记为1指的是数据x和y是直接密度可达,然后利用warshall算法计算该矩阵的可达矩阵,可达矩阵指密度相连的数据。通过warshall算法,将求解密度相连问题转化为求解可达矩阵问题,降低了算法的复杂性。